“When you use your phone to order an Uber or make a doctor’s appointment, it’s likely going through one of our data centers,” Baumann told a Minooka Village Board meeting in January.
“We consider ourselves a utility, like water or sewer or electricity. It has that kind of importance to everyday life,” he said.
But Equinix is not a regulated utility like ComEd or Peoples Gas. Equinix is a publicly traded company whose top shareholders are Wall Street titans such as BlackRock, State Street and Vanguard.
It’s a supplier that’s kept on a tight leash by the big dogs of artificial intelligence, namely, its partners, including Microsoft and Google.
Contrasting opinions here from the corporation’s real estate director and the Chicago Tribune. On one hand, it is hard to imagine life today without the Internet, social media, and smartphones. All that data transmitted through the air requires infrastructure including cables, towers, and data centers.
On the other hand, all of this is not considered a utility in the same way by the federal and state government. Gas, electricity, and water have all sorts of regulations so that everyone can access them. They are considered essential to housing. The right to the Internet does not exist yet. And the nod above to the private market may or may make sense; other utility companies are publicly traded and seek profits.
Is this a convincing argument in the long run? Would local officials and residents be more inclined to approve a data center if they think of like a utility or more like a company?
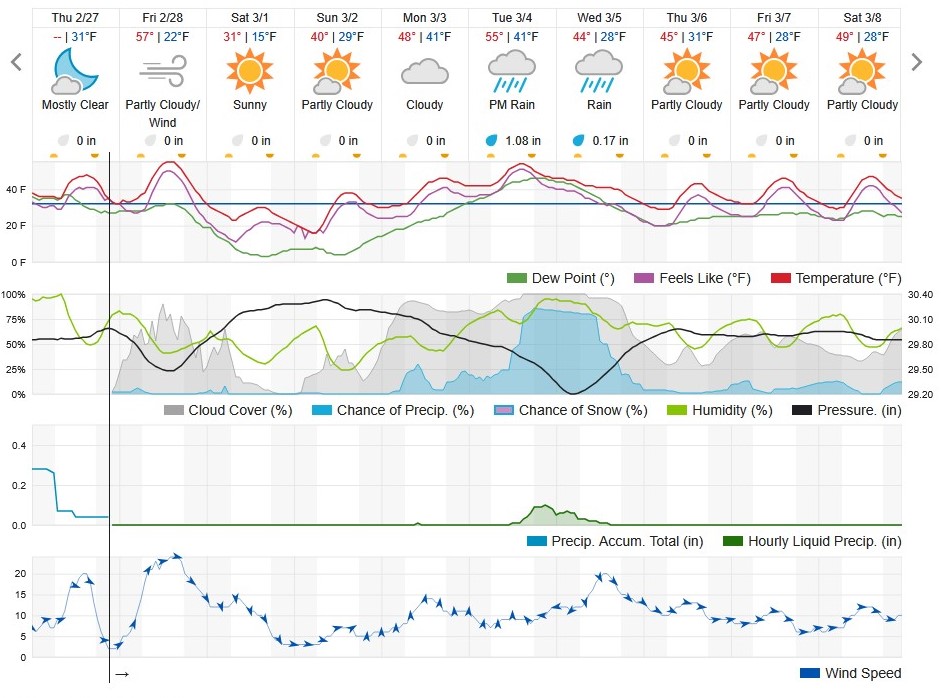
I have tried numerous weather apps and websites over the years searching for an interface that provides all the information I want in a helpful format.
Many platforms seem to want to emphasize the current temperature and conditions and make it harder to see other details. And they want you to view ads.
I eventually found Weather Underground’s ten day forecast. It works best on a bigger screen through their website. Here is what it looked like last night:
This does tell me current conditions – I can see them on the left. And there is a temperature high/low and a graphic at the top. But it also does several other things:
-provides info on upcoming days
-graph lines for temperature, wind chill, dew point, cloud cover, precipitation and wind
-the user can move along those graph lines to see the exact prediction conditions at that time so it can operate like an hourly forecast
Perhaps this is too much information for many. But I don’t need to scroll down and down or click to another screen. I can have a current condition graphic and can see current conditions plus can see trends for the future. This is the weather site I am sticking with (though would be open to trying other options).
The Greater Orlando Aviation Authority on Wednesday took steps toward that future by seeking partners to develop and operate a flying car landing pad — called a vertiport — at the airport. The invitation is expected to publish in March with a 2028 target for a finished product.
The airport expects to put the vertiport on land in the East Airfield region on the northeast side or land on the south side near the train station, according to a news release…
Orlando Mayor Buddy Dyer, a member of the aviation authority, said the city is a global leader in Advanced Air Mobility (AAM) — the technology behind flying cars — and having the hub at the airport makes sense…
He said vertiports may help manage the city’s growth, but that’s much farther off. He envisions starting with a four- to six-passenger vehicle operating out of the airport and eventually corridors for flying cars will follow. The small aircraft are expected to use electric power, and take off and land vertically.
Three thoughts on these plans:
It sounds like Orlando wants to pursue this to contribute to its economic growth. It could become a leader in flying cars. How big of an industry could this be? Americans like cars, Americans dislike traffic…could this be a big growth industry in the coming decades?
The connections between this and the numerous theme parks in the area are intriguing. Would visitors be willing to try these because this is an exciting place to visit? Could the flying cars be linked to Disney or Universal or other partners?
Flying car corridors will be interesting to see. How will they work and where will they be? How visible will they be from the ground? Will they also have gridlock?
Flying cars could be cool but if they lead to similar problems plaguing cars at the moment – traffic, expensive to buy a vehicle and maintain it, etc. – it may not get off the ground.
The weepy confessions are, ostensibly, gestures toward intimacy. They’re meant to inspire empathy, to reassure viewers that influencers are just like them. But in fact, they’re exercises in what I’ve come to call “McVulnerability,” a synthetic version of vulnerability akin to fast food: mass-produced, easily accessible, sometimes tasty, but lacking in sustenance. True vulnerability can foster emotional closeness. McVulnerability offers only an illusion of it. And just as choosing fast food in favor of more nutritious options can, over time, result in harmful outcomes, consuming “fast vulnerability” instead of engaging in bona fide human interaction can send people down an emotionally unhealthy path…
McVulnerability is perhaps an inevitable outcome of what the sociologist Eva Illouz identifies as a modern-day landscape of “emotional capitalism.” “Never has the private self been so publicly performed and harnessed to the discourses and values of the economic and political spheres,” Illouz writes in her book Cold Intimacies. Emotional capitalism has “realigned emotional cultures, making the economic self emotional and emotions more closely harnessed to instrumental action.” That is, not only does emotionality sell goods, but emotions themselves have also become commodities…
McVulnerability, from whichever angle you look at it, is the opposite of generous. It doesn’t require risk. It may pretend to give, but ultimately, it takes. And it leaves most of its consumers hungry for what they’re craving: human connection—the real thing.
The “Mc-” prefix makes sense given the popularity of McDonald’s. The way the term is deployed above seems similar to how the term McMansion has been used for several decades. McVulnerability is a pale substitute for true vulnerability. It is vulnerability in a popular and commodified form.
But can the term stick? It may depend on the popularity of such viral videos. Do they have staying power or will they be gone to be replaced by other trending videos? Will this pattern last for years? Or there might be other terms that describe these videos. Or the critique may not stick – what if most watchers see the emotional expressions as real and valuable? If such expressions become the new normal, perhaps McVulnerability is here to stay.
We’ll have to wait and see. McDonald’s will go on and plenty of other mass produced products and experiences will come along. Which ones will live on in “Mc-” infamy?
The temporary loss of TikTok in the United States a few days ago was a sort of natural experiment and it did make me wonder: what if social media was gone tomorrow?
Numerous areas of life would be affected. Here are just a few:
People and companies making money. Whether through ads or selling things or streaming, money flows through social media.
How people use their time. What would people do instead? Watch more TV (this was a primary activity before social media existed)? Talk to the people around them? Go outside?
Where people get information, whether about people they know or the news or the standard information people today are supposed to know (ranging from viral videos to celebrity updates to conflict on the other side of the world).
Connections to people. The easy access to people through posts and profiles and social media interactions would be gone. Could the connections happen through other mediums?
A whole set of rituals, norms, and discussions would be lost. They could not be accessed or scrolled through. All that time managing images and interactions goes away.
Even with all these changes (which would take some time to get used to), this question might be most important: would life be better?
All said, it is a relatively small segment of the population that is “very online” with respect to social media, or that regularly consumes jouranalistic media in virtually any format (TV, online, print, podcasts) – let alone engaging with research by think tanks, nonprofits, activists, or academics. Mostly, it’s people like us. Virtually the entire political and cultural melodrama carried out in academia, policymaking spaces, media outlets, and social networking sites it carried out among symbolic capitalists. The views and priorities of most others are simply unrepresented in these spaces. And for their part, most of those who are not symbolic capitalists are not particularly interested in the highly idiosyncratic struggles we invest so much of ourselves into. (195)
This seems consistent with earlier reports I’ve seen. Social media activity is driven by a small set of users who are not representative of the American population at large.
This could be helpful to keep in mind when wondering if social media is fragmented or how widespread a trend is or whether algorithms could be driving people to different corners of the Internet. These features might be true AND social media as a whole might be driven by a small set of people who share particular positions and practices.
(Read more about the definition of symbolic capitalists here.)
Just how accurate are those numbers, though? Until the house actually trades hands, it’s impossible to say. Zillow’s own explanation of the methodology, and its outcomes, can be misleading. The model, the company says, is based on thousands of data points from public sources like county records, tax documents, and multiple listing services — local databases used by real-estate agents where most homes are advertised for sale. Zillow’s formula also incorporates user-submitted info: If you get a fancy new kitchen, for example, your Zestimate might see a nice bump if you let the company know. Zillow makes sure to note that the Zestimate can’t replace an actual appraisal, but articles on its website also hail the tool as a “powerful starting point in determining a home’s value” and “generally quite accurate.” The median error rate for on-market homes is just 2.4%, per the company’s website, while the median error rate for off-market homes is 7.49%. Not bad, you might think.
But that’s where things get sticky. By definition, half of homes sell within the median error rate, e.g., within 2.4% of the Zestimate in either direction for on-market homes. But the other half don’t, and Zillow doesn’t offer many details on how bad those misses are. And while the Zestimate is appealing because it attempts to measure what a house is worth even when it’s not for sale, it becomes much more accurate when a house actually hits the market. That’s because it’s leaning on actual humans, not computers, to do a lot of the grunt work. When somebody lists their house for sale, the Zestimate will adjust to include all the new seller-provided info: new photos, details on recent renovations, and, most importantly, the list price. The Zestimate keeps adjusting until the house actually sells. At that point, the difference between the sale price and the latest Zestimate is used to calculate the on-market error rate, which, again, is pretty good: In Austin, for instance, a little more than 94% of on-market homes end up selling for within 10% of the last Zestimate before the deal goes through. But Zillow also keeps a second Zestimate humming in the background, one that never sees the light of day. This version doesn’t factor in the list price — it’s carrying on as if the house never went up for sale at all. Instead, it’s used to calculate the “off-market” error rate. When the house sells, the difference between the final price and this shadow algorithm reveals an error rate that’s much less satisfactory: In Austin, only about 66% of these “off-market Zestimates” come within 10% of the actual sale price. In Atlanta, it’s 65%; Chicago, 58%; Nashville, 63%; Seattle, 69%. At today’s median home price of $420,000, a 10% error would mean a difference of more than $40,000.
Without sellers spoonfeeding Zillow the most crucial piece of information — the list price — the Zestimate is hamstrung. It’s a lot easier to estimate what a home will sell for once the sellers broadcast, “Hey, this is the price we’re trying to sell for.” Because the vast majority of sellers work with an agent, the list price is also usually based on that agent’s knowledge of the local market, the finer details of the house, and comparable sales in the area. This September, per Zillow’s own data, the typical home sold for 99.8% of the list price — almost exactly spot on. That may not always be the case, but the list price is generally a good indicator of the sale figure down the line. For a computer model of home prices, it’s basically the prized data point. In the world of AVMs, models that achieve success by fitting their results to list prices are deemed “springy” or “bouncy” — like a ball tethered to a string, they won’t stray too far. Several people I talked to for this story say they’ve seen this in action with Zillow’s model: A seller lists a home and asks for a number significantly different from the Zestimate, and then watches as the Zestimate moves within a respectable distance of that list price anyway. Zillow itself makes no secret of the fact that it leans on the list price to arrive at its own estimate…
So the Zestimate isn’t exactly unique, and it’s far from the best. But to the average internet surfer, no AVM carries the weight, or swagger, of the original. To someone like Jonathan Miller, the president and CEO of the appraisal and consulting company Miller Samuel, the enduring appeal of the Zestimate is maddening. “When you think of the Zestimate, for many, it gives a false anchor for what the value actually is,” Miller says.
Multiple factors are at play here. Who has what information about housing and housing values? How is the value calculated? And what is the distribution of the comparison of the estimated value to the actual sales value? Some of this involves data, some involves algorithms.
It also sounds like part of the story is that Zillow has built one of the more effective brands in this space. Even if the estimates are not exactly right, people are drawn to Zillow. What would happen if competitors advertised that they are more accurate? Would this be enough to move people from using Zillow?
Given all of this, who can build the most accurate number might not be the “winner.” Is the goal to best model the housing market or is the goal to attract users? These two goals might go together but they might not.
Elon Musk‘s company SpaceX is looking to make Starbase, Texas, the home of its starship development and production facility, an official town.
Starbase is currently an unincorporated community within Cameron County, in the Rio Grande Valley…
“To continue growing the workforce necessary to rapidly develop and manufacture Starship, we need the ability to grow Starbase as a community. That is why we are requesting that Cameron County call an election to enable the incorporation of Starbase as the newest city in the Rio Grande Valley,” Starbase general manager Kathryn Lueders said in a letter to Cameron County Judge Eddie Trevino.
To make Starbase official, Trevino must order a special election to incorporate the community as a Type-C Municipality. Registered voters in the area must approve the change.
According to Lueders, incorporating Starbase will streamline the process to make Starbase a “world-class place to live” and enable the Starship program to “fundamentally alter humanity’s access to space.”
A few thoughts about what sounds like an interesting community:
What will make it different from other American or Texas communities? Will it have a unique physical layout? Will day-to-day life be different than other communities? Beyond the launch facilities, what might set this apart?
Is Starbase a company town or just a community dominated by one industry? These sorts of communities can have interesting histories given their reliance on the rises and falls of the local industry.
Think of the branding and merchandise potential of the community. Shirts, hats, shot glasses, and more carrying a Starbase, Texas script or logo.
Part of the fixation on cultural algorithms is a product of the insecure position in which cultural gatekeepers find themselves. Traditionally, critics have played the dual role of doorman and amplifier, deciding which literature or music or film (to name just a few media) is worthwhile, then augmenting the experience by giving audiences more context. But to a certain extent, they’ve been marginalized by user-driven communities such as BookTok and by AI-generated music playlists that provide recommendations without the complications of critical thinking. Not all that long ago, you might have paged through a music magazine’s reviews or asked a record-store owner for their suggestions; now you just press “Play” on your Spotify daylist, and let the algorithm take the wheel.
If many culture industries struggle to know what will become popular – which single, film, book, show, or product will become wildly successful and make a lot of money? – critics can be one way to try to figure this out. What will the influential critics like? Will they champion particular works (and dislike others)?
Might we get to some point where we see algorithms as critics or acting with judgment and discernment? Right now the recommendation algorithms are a “black box” that users blindly follow. But what if the algorithms “explained” their next step: “You like this song and based on this plus your past choices, I now recommend this.” Or what if you could have a “conversation” back and forth with the algorithm as you explain your interests and it leads in particular directions. Or if the algorithm mimics the idiosyncrasies a human critic would have.
I wonder about the role of friends and social contacts in what they recommend or introduce people to. At their height, could cultural critics move people away from the choices of family and friends around them? In today’s world of recommending algorithms, how often does the patterns of friends and acquaintances move people in different directions?
Widely shared on social media, the atmospheric black and white shots — a mother and her child starving in the Great Depression; an exhausted soldier in the Vietnam war — may look at first like real historic documents.
But they were created by artificial intelligence, and researchers fear they are muddying the waters of real history…
For now, Amaral and Teeuwissen believe they can still tell fake historical images from real ones just by looking at them.
AI-generated photos often have tell-tale glitches: too many fingers on a hand, missing details — such as the lack of a propeller on the Wright brothers’ plane — or, on the other hand, compositions that are too perfect.
“AI-generated pictures can recreate the look, but they miss the human element, the intent, the reason behind the photographer’s choices,” said Amaral.
With AI text and images, history could be all redone. What is available online, often the first or primary source for many, could provide different historical accounts and evidence.
Of course, history to some degree is always in flux as different actors and different contexts affect how we understand what happened in the past. There are things that happened and then perceptions and interpretations of those happenings that often take time to develop and solidify. AI joins an already existing process.
Do AI images then pose a unique threat to historical knowledge and narratives? If history is primarily created and understood through images online, perhaps. Will others find ways to demonstrate that certain images are truly from the past?